Performance of Python remains a critical challenge in data science due to the exponential growth of datasets. As businesses and industries, from AI to life sciences to financial services, leverage big data, the massive volume, velocity, and variety create opportunities and bottlenecks. Python performance issues can impact workflows ranging from data ingestion and storage to processing and analysis, demanding novel solutions that improve scalability without sacrificing accuracy or reliability.
Traditional tools and methodologies that once sufficed are now straining under the weight of these massive datasets. As a result, data scientists and engineers are compelled to seek novel solutions that can improve performance of Python and scalability without compromising on accuracy or reliability. This pursuit of innovation has given rise to a new frontier in data science, where cutting-edge technologies and techniques are being leveraged to overcome these challenges and unlock the full potential of data-driven insights.
One of the enduring challenges in data science revolves around what is often referred to as the “two language problem“, which arises from the dichotomy between the ease of use and flexibility offered by high-level languages like Python and the performance and scalability requirements demanded by large-scale data processing and analysis tasks.
Python has emerged as the lingua franca of data science, celebrated for its intuitive syntax, vast ecosystem of libraries, and vibrant community. It’s the go-to choice for data wrangling, exploratory analysis, and model development, thanks to libraries like NumPy, Pandas, and scikit-learn that streamline and greatly simplify the development cycle for these tasks. The interactive nature of Python through tools like Jupyter Notebooks further enhances its appeal, fostering a productive workflow for data scientists to iterate and experiment.
However, Python as a language is slow. It runs in an interpreter which is much slower than the native code that low-level languages like C, C++ or Rust compile to. Thus, a dichotomy between performance of Python and ease of use emerges:
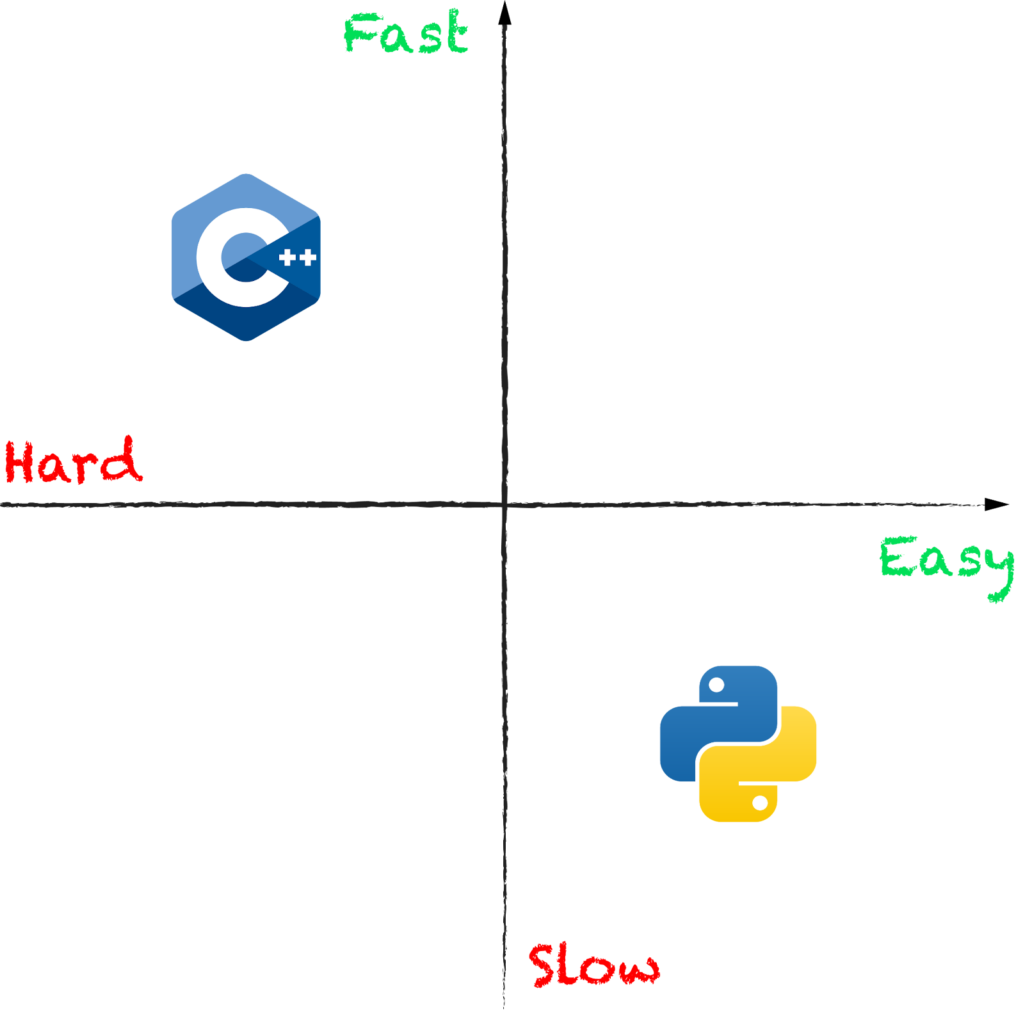
As a result, data scientists often find themselves locked into a cumbersome development process where initial work is done in Python, then code is rewritten in a low-level language like C++ to scale, run in production, take advantage of hardware and so on.
That’s where Exaloop comes in, offering the best of both worlds:
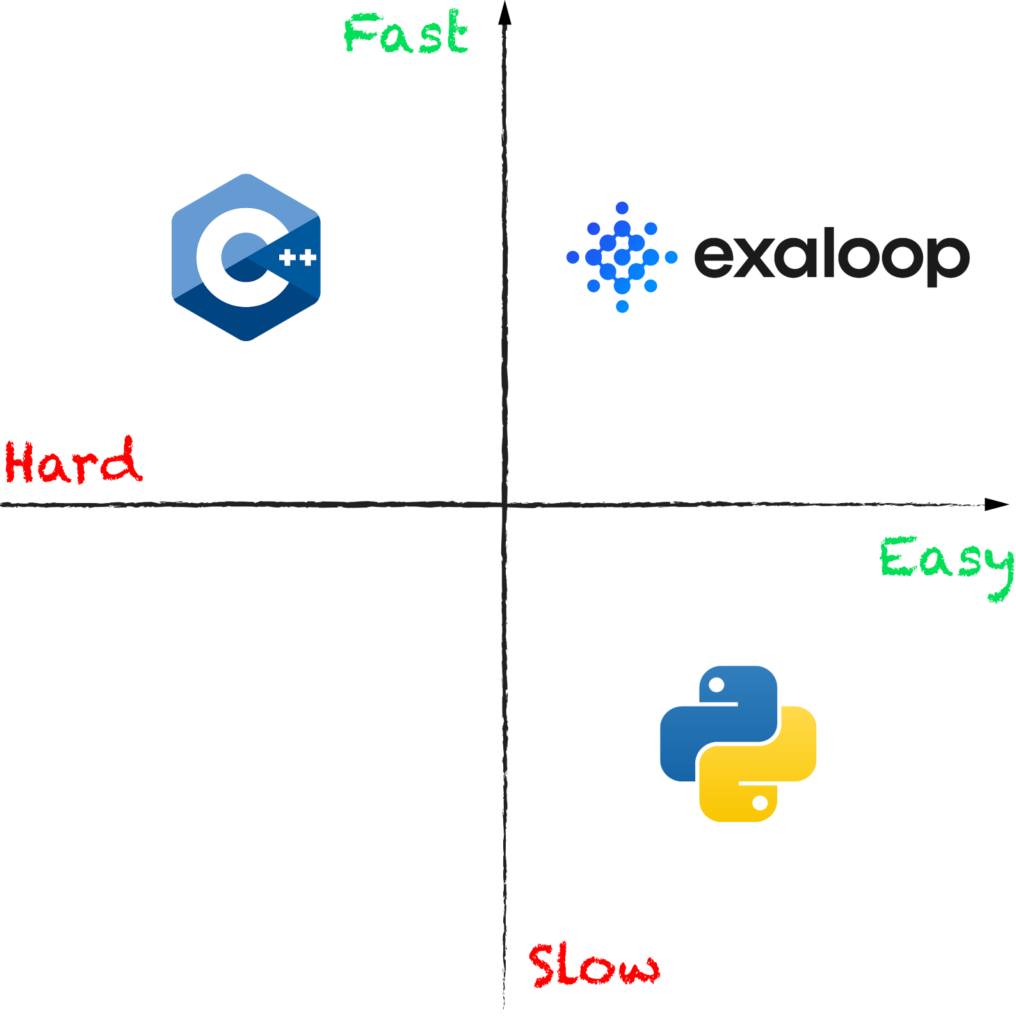
In this blog, we’ll explore how Exaloop brings performance and scalability to Python, empowering data scientists to use their main workhorse language not only for experimenting and exploring data, but also for scaling and running their code in production.
Python, minus the interpreter
While low-level languages like C compile to native code that runs directly on the CPU, Python compiles to bytecode that is executed by another program called an interpreter. That means a simple statement like “a + b” that might take a single clock cycle with C/C++, can take an order-of-magnitude longer in Python when accounting for the overhead of the interpreter dispatching the corresponding bytecode operation, checking data types, handling the result and so on.
One of the core features of Exaloop is that it eliminates the interpreter altogether, compiling Python code directly to native machine code just like C++. As a result, a Python program that runs through Exaloop has the same performance (or, in fact, sometimes even better) than an equivalent program written in C++.
This approach to compiling Python has several important benefits:
- Raw performance: Of course, raw performance of Python is the most immediate and obvious benefit, and usually translates to 10-100x speedups out of the box.
- None of Python’s limitations: No reliance on standard Python means we break free of its limitations, like the infamous “Global Interpreter Lock” (GIL) which we’ll discuss later.
- No unnecessary object overhead: Python objects need to carry around extra data, including type information (for figuring out how to operate on the object) and reference count (for determining if the object is no longer being used and can therefore be deleted). Objects themselves are actually passed around as pointers, and the object data itself (along with the aforementioned “metadata”) lives in heap-allocated memory. Exaloop eliminates all of this metadata and indirection, reducing the memory footprint of programs in the process.
- Opportunities for optimizations: Exaloop analyzes the entire program end-to-end, which enables a variety of powerful compiler optimizations like inlining, eliminating unused code and so on. For example, take a look at this code:
a = 0
for i in range(100_000_000):
a += i
In plain Python it takes ~6 seconds to execute, but with Exaloop it takes… zero seconds! The entire for-loop is eliminated and pre-computed during compilation. This is undoubtedly just a toy example, but it highlights an important difference between how plain Python and Exaloop execute code.
Parallelism and multithreading for Performance of Python: the dreaded GIL
The Global Interpreter Lock, or GIL, is undoubtedly one of the most infamous features of Python, and substantial effort has been put into trying to remove or alleviate it. In essence, the GIL simply restricts Python bytecode execution to a single thread, meaning effective multithreading is not possible in Python. (Python does have a multithreading module that can occasionally be useful for I/O- or network-bound applications, but we won’t get into that here.)
The conventional solution for parallelism in Python is to use multiprocessing instead of multithreading, meaning multiple processes are spawned to work on a task in parallel. But that poses major challenges of its own, especially when it comes to sharing data between processes, which usually involves serialization and costly I/O operations, and generally does not scale well.
Since Exaloop was built from the ground up independently of standard Python, it doesn’t have a GIL and supports full multithreading. For example, Exaloop lets you distribute iterations of a loop between threads with one line of code:
@par(num_threads=12)
for i in range(N):
process(i)
The “@par” line tells Exaloop to run the loop using 12 threads. Exaloop also supports fine-grained locking and automatic reduction operations. The “@par” annotation also supports the full gamut of OpenMP options.
GPUs
GPU utilization has seen a meteoric rise across a range of industries, especially with the recent AI revolution. While some Python frameworks like PyTorch support GPUs for AI/ML training or inference, Exaloop makes it possible to write and use GPU kernels directly in plain Python for any application. This is made possible via the same “@par” syntax:
@par(gpu=True)
for i in range(N):
process(i)
Notice the new “gpu=True” argument. Exaloop will take the body of the loop, factor it out into a GPU kernel, and automatically insert code to invoke the kernel across the iterations of the given loop. This capability is again made possible by Exaloop’s unique approach to code generation and execution: the fact that Exaloop has a full view of the entire program even across function and library calls enables it to generate native PTX code that can run on the GPU just like CUDA does (but, without the headache!).
Libraries, C extensions and missed opportunities
Python’s popularity is owed in no small part to its vast and comprehensive ecosystem of libraries. Whatever data science task you’re undertaking, there’s probably a Python library out there that can make your life easier. Exaloop is compatible with all Python libraries out-of-the-box through its built-in Python interoperability (although, it’ll run them through the standard Python interpreter by default).
Some Python libraries use C extensions for performance reasons, meaning key functionality is implemented in C and exposed in Python. NumPy is a prime example of this: core array functionality and operations (e.g. sum, matrix multiplication, etc.) are implemented in C but usable via the “ndarray” class in Python. This pattern certainly helps with performance of Python, but nevertheless leaves a lot on the table. Calling opaque C functions from Python prevents optimization opportunities like inlining and operator fusion. Moreover, C extensions are still subjected to Python’s core limitations like the GIL.
Exaloop offers new, optimized implementations of several core Python libraries, including NumPy and Pandas, that are fully compiled and work seamlessly with Exaloop’s other features like multithreading and GPU. They also incorporate library-specific optimizations, like fusions for NumPy or DataFrame query rewrites for Pandas (which can yield 50x speedups alone). While speedups in general are application-dependent (e.g. just multiplying two 100k-by-100k matrices will have the same performance with both Python and Exaloop), order-of-magnitude performance of Python gains are commonplace for many real-world applications. (As an interesting aside, these libraries are actually implemented in Exaloop itself!)
Conclusion – the data science stack reimagined for Python performance and scalability
In many ways, Exaloop reinvents the data science stack with performance of Python and scalability in mind. From the language, to libraries, to Exaloop’s UI and cloud-based platform—all of these components were designed to bridge the gap between simplicity and performance in the modern world of big-data and AI. In this blog, we’ve covered just a few of the ways in which Exaloop achieves this goal. If you want to try Exaloop for yourself and see these features in action, join our waitlist!
Conclusion
Python’s position as the leading language for AI programming with Python is well deserved. Its clarity, vast ecosystem, and supportive community streamline the development of cutting-edge AI solutions for data scientists. Across a variety of industries, Python and AI are driving innovation and optimizing processes, transforming the way we approach challenges.
As the complexity of AI projects grows, platforms like Exaloop further empower data scientists by removing performance barriers. Using Python’s familiar syntax, enhanced by Exaloop’s optimizations, unlocks even greater potential for groundbreaking AI-driven discoveries. If you’re ready to explore the frontiers of AI programming with Python in data science, the combination of Python and Exaloop opens up a future of accelerated development and transformative insights. Try Exaloop today to experience high-performance Python.
FAQs
Will Exaloop work on my existing Python codebase?
Yes – there are in fact several different ways to use Exaloop:
- As an end-to-end solution – works best for smaller programs or scripts.
- Within a larger Python codebase – you can annotate performance-critical functions to be run through Exaloop, and thereby leverage Exaloop’s features like parallelism.
- To write Python extensions – best if you’re looking to replace C extensions or Cython.
The Exaloop Platform also includes tools to make integrating Exaloop into an existing codebase easier, like AI Optimizer.
How can I tell if my application will benefit from multithreading or GPU?
Exaloop makes it easy to incorporate these parallelization techniques without relying on low-level programming or manual optimizations, and thereby offers an avenue to determine whether they’re worthwhile for your specific use case. As a good rule of thumb:
- Multithreading works best for operations that can be divided into independent units of work that interact minimally with one another.
- GPUs work best for massively parallel operations that don’t involve complex control flow. Of course, certain operations like file I/O aren’t suitable for GPUs.
Can I use my own Python libraries with Exaloop?
Yes – Exaloop supports any Python library out of the box by running it through the standard Python interpreter, including your own libraries. As a result, you can use your own libraries as they are or even optimize them with Exaloop.
